News
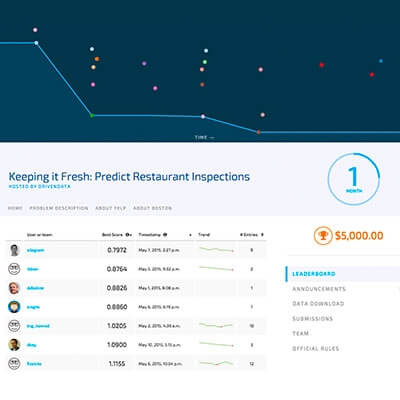
By parsing the words, phrases, and ratings from Yelp, DrivenData's crowdsourced tool helps officials target inspections to the most probable violators.

Preventing foodborne illness by harnessing social media is just one outcome being advanced by DrivenData, a new venture spawned at Harvard School of Engineering and Applied Sciences (Image courtesy of Simon Abrams/Flickr Creative Commons)
William “Buddy” Christopher has a problem. As commissioner of Boston’s Inspectional Services Department, he is responsible for enforcing health regulations at the city’s 3,043 restaurants. But regularly getting to all of them is a tall order for his team of 18 inspectors.
If there were a way for Christopher to predict which establishments are most likely to require enforcement action, his inspectors could check on those restaurants more frequently and make fewer trips to the ones that adhere scrupulously to regulations.
It is a perennial challenge faced by municipalities across the country. Now, social media might provide a solution. By parsing the words, phrases, and ratings from Yelp, the platform that lets consumers post reviews of the businesses they patronize, officials could target inspections to the most probable violators. But how can a strapped city agency muster the computational horsepower to extract useful information from the massive trove of data—“Yelpers” have written more than 77 million local reviews over the past decade—and match it to the hundreds of eating establishments under its jurisdiction?
One approach might be to hire an expert in data science. A company called DrivenData has a better idea: frame the pertinent questions, post raw data online, and recruit a volunteer army of hundreds of the best data scientists to solve the puzzle. The person who creates the most predictive algorithm wins a cash prize and bragging rights in the data science community. All of the contestants get to exercise their creative skills—and get the satisfaction of knowing they are helping to address an important public need.
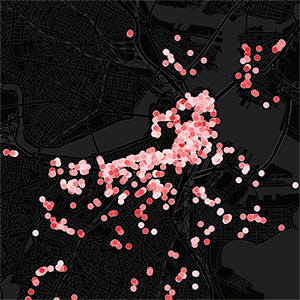 Computer-generated map of health violations at Boston restaurants
Computer-generated map of health violations at Boston restaurants
Using this crowdsourcing model, DrivenData aims to unlock the potential of big data to help mission-driven non-profits and public sector agencies operate more effectively—and have more impact. Call it activism through algorithms.
The startup was spawned at the Harvard School of Engineering and Applied Sciences (SEAS), where co-founders Peter Bull and Isaac Slavitt were classmates in the computational science and engineering master’s program. Students in the program are asked to apply the skills they learn to solve a problem using real data. Bull and Slavitt realized that most of the readily available data-crunching opportunities had to do with big commercial enterprises
“Peter and I were looking around for a great problem to work on, one with social impact,” recalls Slavitt, who will soon conclude service in the U.S. Coast Guard, where he’s been an operations research analyst in the Washington, D.C. headquarters.
“There are organizations that don’t have the capital and resources to hire full-time professional data scientists and we thought, if we’re going to essentially be working for free, we’d like to work for one of those organizations,” says Bull, who is now DrivenData’s lone full-time employee. “We looked around for the right organizations; that’s where the idea [of starting the company] came from. Our initial desire for data sets was superseded by finding a real need and real problem that we think we can address.”
A third co-founder, Greg Lipstein, who was Bull’s college roommate and will earn an MBA from Harvard Business School in May, brought needed business operations experience to the team. (Slavitt and Bull also persuaded Lipstein to elevate his technical game by taking CS50, the famously popular introduction to computer coding course taught by SEAS Professor of the Practice David Malan.)

An emerging data literacy gap
Non-profits and government agencies, just like the commercial sector, are collecting more data than ever before. In fact, a 2013 executive order signed by President Obama made open and machine-readable data the new default for federal government information, and many state and local governments are following suit.
But a large data literacy gap has emerged in the social and government sectors. “They’re collecting the data but they don’t know what the data can do for them, what questions to ask of it,” Bull says. “Even if they know what questions to ask, they’re not able to get those questions answered because the shortfall in supply means data scientists are going to be expensive for a very long time. The social sector is going to lag even further behind.
“A competition seemed like a really good way of connecting these kinds of organizations to that kind of talent, both in terms of translating what the nonprofits need into something the data scientists would understand and giving them real solutions that they can use.”
DrivenData’s first competition attracted nearly 300 participants, including many of the top people in the field. “We are surprised by the overall caliber of submissions we get,” Slavitt says. “Not everyone is going to win the competition, but part of the attraction of DrivenData is that even if you don’t win, it was for a good cause.”
The cause behind that initial foray was Education Resource Strategies (ERS), a Boston-area non-profit consultancy that advises large school districts on how to spend their money more strategically.
“One of the primary ways we work with a district is to categorize all of their spending into standardized buckets so that school leaders can compare their spending in an apples-to-apples way,” says Dan Turcza, who represented ERS on the project. “Knowing how you’re spending relative to your peers is always very interesting and generates a lot of insights for our partners.”
But for ERS, the initial step of characterizing a district’s spending practices is an excruciatingly tedious process, requiring hundreds of man-hours to go literally line-by-line in a spreadsheet and classify expenditures. Participants in the DrivenData competition were able to come up algorithms that can predict, with accuracy in the 90-95% range, how spending should be categorized. The DrivenData team is now working to deliver a software tool based on the winning entry that will allow ERS staffers to feed in the data and then vet the model’s recommendations, eliminating a huge amount of up-front manual effort.
ERS is excited about the obvious near-term benefits, as well as the potential to expand the organization’s impact in the future. “This opens up this kind of analysis to many, many more school districts,” Turcza says. He adds: “I am impressed and inspired by how many organizations could apply this kind of thinking to their work. There’s a lag in terms of organizations that are otherwise very intelligent in how they’re doing their work but just don’t have access to this kind of technique. It underscores the need for more data scientists.”
Creating a community
Building a pipeline of socially-minded data scientists is one of the DrivenData’s core goals.
“Our mindset has grown; we want to solve the big-picture data literacy and data capacity problems in the social and public sectors,” Bull says. “We think competitions are a great mechanism to do that right now, but our goal is to do more, to serve that community in other ways.”
“There is a huge class of people we’d like to have on board who are data science learners, who are either in a grad school program or undergraduates or working in a related career field but looking to exercise their data science skills,” Slavitt says.
Bull adds: “In an ideal world, students and professors in data science would say, ‘Hey, there are really cool problems in the social sector that I could work on. I don’t have to go to work at Google or Facebook or Microsoft to be a data scientist and work on really cool things.’ We’d love in long term to increase capacity in that way, getting more and more people to see what they can do and getting them involved in those types of projects.”
Before a competition is launched and freelance data scientists are unleashed on a problem, the DrivenData team invests a lot of time working with a nonprofit to understand its needs. What are the biggest operational challenges? Does the organization possess a large quantity of the right kind of data? Is there a good predictive question that can be framed? Can using the available dataset to solve the question yield actionable results, results that will advance the mission and have lasting impact?
“You have to think creatively about what you can do with the data, what are the problems you can solve,” Bull says. “For us, that’s the really fun part – to think about what we really can learn.”
For example, one recent project asked competitors to build models based on a comprehensive data set compiled by the Centers for Disease Control and Prevention that would help the Planned Parenthood Federation of America and its sister organization the Guttmacher Institute predict how demographic and life experience variables affect women’s health care choices. Leading up to the contest, Slavitt and Bull spent weeks assessing how data from the CDC’s National Survey of Family Growth could be used, algorithmically, to inform the national non-profit’s strategic planning.
“We took the data set, focused in on sub-sets that we were interested in, and then did all of the cleaning and prep work necessary to make it possible for the data scientists and developers to create novel predictive models,” Slavitt says.
Screenshot from the DrivenData website displays the status of crowdsourced competitions.
Putting winning results in practice
DrivenData’s post-competition role varies by project. In some cases, such as the school budget labeling project for ERS, DrivenData will hand off software that is easy for an organization to use for future decision making. In other instances, the team will work collaboratively with the client organization to integrate the best model.
During the six weeks of the Planned Parenthood competition, nearly 500 data scientists made 1,332 submissions. An evaluation engine on the DrivenData platform ranked the models based on how well they predict data that had been withheld from the competitors. Now that a winner has been crowned, the DrivenData team is closing the loop by delivering code and write-ups for top-performing statistical models that the Guttmacher Institute will use for continued research on reproductive health trends.
“We’d like to be in a place where a good portion of our competitions turn into actual tools, something the organization can use to make smarter decisions,” Bull says.
Since launching the platform in October 2014, DrivenData has averaged one to two competitions per month. The biggest barrier to ramping up the rate now is sourcing the problems for freelancers to tackle. This summer, a part-time data science fellow will join the team, and the venture is in accelerator programs at the university’s Innovation Lab (iLab) and Harvard Business School’s Rock Center for Entrepreneurship.
“We’ve been experimenting with different ways to streamline the process, to make it very parallelizable so that we can run multiple concurrent competitions,” Slavitt says.
The young company has already made a promising start to fulfilling its mission to use data and computational techniques to make the world a better place.

Topics: Entrepreneurship, Computer Science, AI / Machine Learning
Cutting-edge science delivered direct to your inbox.
Join the Harvard SEAS mailing list.


