News

Teammates Kate Zhou, a first-year mechanical engineering Ph.D. candidate, and Amil Merchant, A.B. ’19, an applied math concentrator, try different algorithmic approaches to narrow down the best method to identify medical fraud. (Photo by Adam Zewe/SEAS Communications)
Health care fraud costs the United States nearly $100 billion each year, a sizable piece of the $3 trillion the nation spends annually on care, according to the Department of Justice. Schemes continue to grow in scope and complexity, stretching the limits of traditional fraud identification techniques.
Machine learning offers more efficient tools to smoke out fraudsters, as students from the Harvard John A. Paulson School of Engineering and Applied Sciences (SEAS) learned during the recent ComputeFest 2018 Student Data Challenge, organized by Institute for Applied Computational Science (IACS).
During the nine-hour hackathon, student teams put their computational skills to the test in a race against the clock, using machine learning techniques to detect fraudulent insurance claims. Presented with data from more than 18,000 health care providers, the open-ended problem challenged students to devise, test, and then refine the best algorithmic technique to identify fraud.
The winning team, consisting of Xuefeng Peng, M.E. ’19, a computational science and engineering student, and T.H. Chan School of Public Health master’s students Yi Ding and Linying Zhang, was able to find fraud with 95.7 percent accuracy. They used an autoencoder, a type of neural network, which learned common patterns in the dataset to decode genuine data points. Since the autoencoder was unable to decode anomalies, it was sensitive to fraudulent claims, Peng explained.
“I think the attribute that contributed most to our success is cohesive team work,” said Peng. “After getting to know the data format and requirements, we split the work in a very efficient and effective fashion—data preprocessing, data engineering, and model fine-tuning. All three of us took a part, and we were able to keep optimizing our results with a clear pipeline.”
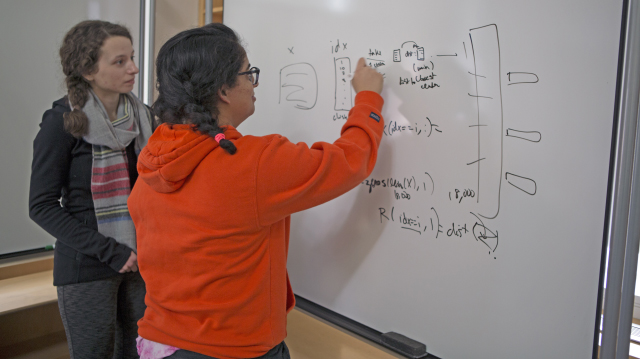
Tara Sowrirajan, a Ph.D. candidate in computer science, and Jovana Andrejevic, a Ph.D. candidate in applied physics, use a whiteboard to work out a complicated problem during the IACS ComputeFest 2018 Student Data Challenge. (Photo by Adam Zewe/SEAS Communications)
One of the biggest challenges resulted from the unsupervised nature of this machine learning problem; data were not labeled, so students had no examples of fraudulent claims on which to base their models.
Teammates Amil Merchant, A.B. ’19, an applied math concentrator, and Kate Zhou, a first-year mechanical engineering Ph.D. candidate, scoured the web for examples of medical fraud, such as overbilling or prescribing too many drugs.
“You can’t just look up the answer to this, like you would a problem set in class,” Zhou said. “It requires a lot of research. I had never considered how these sorts of calculations or estimates for detecting fraud are actually done in real life.”
Another team, comprised of visiting graduate student Christoph Kurz, and Chan School graduate students Hannah James and Anna Zink, tried two approaches in parallel—a linear regression model and a random forest algorithm—to study patterns and distinguish outliers. The students were surprised to find that the simplest technique, linear regression modeling, yielded the best results.
“There is so much variation in spending and health care costs, so there are natural variations in the numbers,” James said. “Behind these numbers are people with diseases and conditions, so this entire data set is explained by more information than we have.”

Chan School graduate students Hannah James and Anna Zink, and visiting graduate student Christoph Kurz, discuss the best ways to distinguish outliers in the data. (Photo by Adam Zewe/SEAS Communications)
The massive data set included 86 features, such as percentage of a provider’s patients who suffer from depression or diabetes. Representing those features in a model through linear and nonlinear combinations was a challenge, said Alexander Munoz, A.B. ’18, an applied math concentrator.
Each team was able to submit an answer three times per hour, but only received feedback on how accurate their results were collectively. Using their most recent feedback, Munoz and teammates Eshan Tewari, A.B. ’21, and statistics Ph.D. candidate Niloy Biswas considered which features to include in the next iteration of their model.
“Doing unsupervised problems requires you to explore the space of data considerably more than you would otherwise. That is something new to all of us,” Tewari said. “Anomaly detection in an unsupervised way has applications in tons of different fields. Learning all the underlying algorithms is helpful.”
The challenge was designed to teach students some fundamental machine learning techniques, while emphasizing their practical applications, said competition architect Marouan Belhaj, an IACS Fellow.
Many students had never encountered an unsupervised problem before, but those are the types of situations fraud detection agents often face, where billions of dollars and millions of lives are at stake. With so many ways to trick the system, machine learning is an ideal method to detect fraud quickly and precisely, while there is still time to intervene, he said.
“In real-world fraud detection, you rarely get feedback from inside the company about how your model is performing,” he said. “To improve the model is very difficult. You really need to think like a hacker or someone trying to defraud the system to understand which techniques you might use to trick the system and then try, through the modeling, to see if your results actually confirm your ideas.”

For Alexander Munoz, A.B. ’18, an applied math concentrator, Eshan Tewari, A.B. ’21, and statistics Ph.D. candidate Niloy Biswas, one of the biggest challenges was determining which features to include in their model. (Photo by Adam Zewe/SEAS Communications)
Topics: AI / Machine Learning, Computer Science, Events
Cutting-edge science delivered direct to your inbox.
Join the Harvard SEAS mailing list.
Press Contact
Adam Zewe | 617-496-5878 | azewe@seas.harvard.edu


